
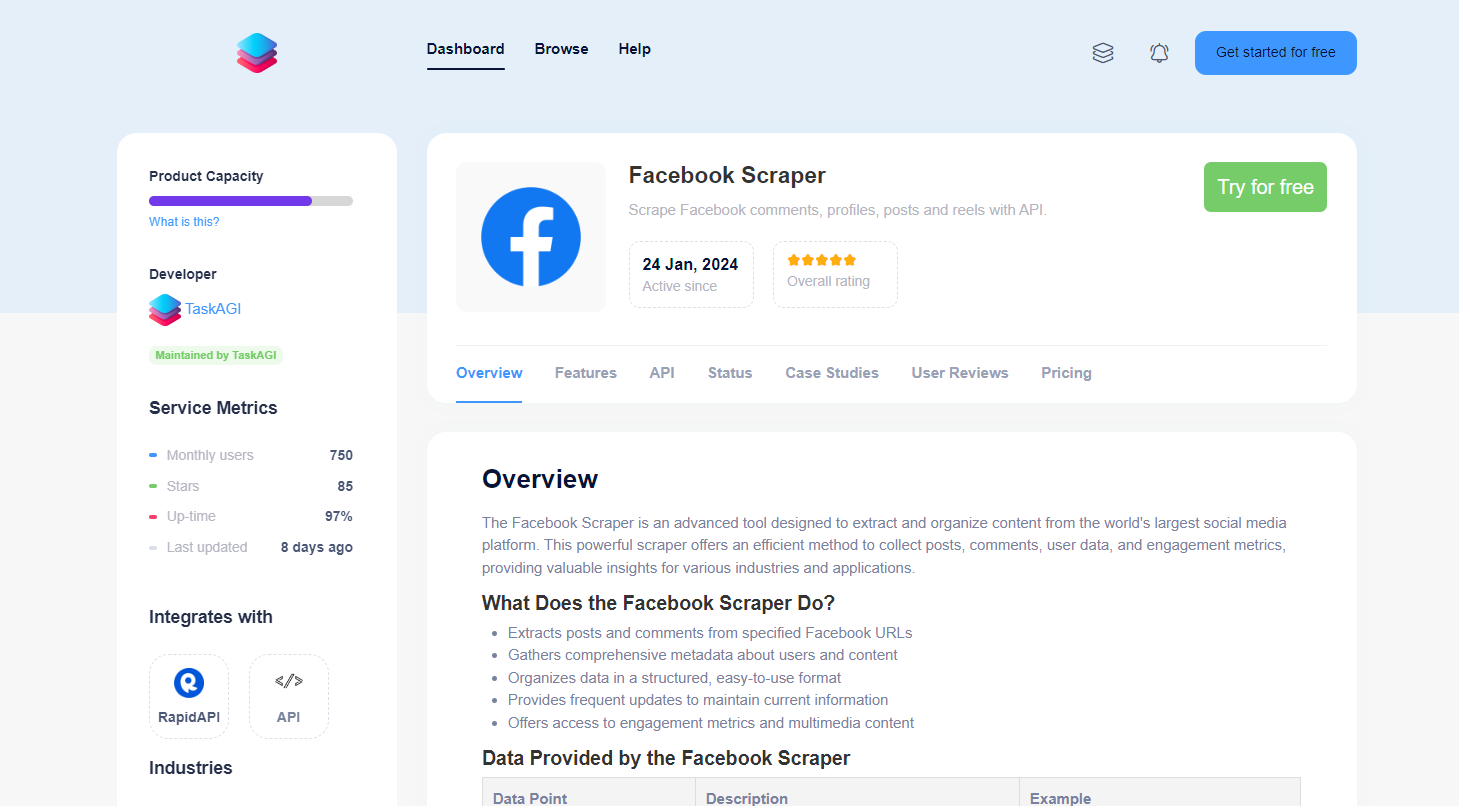
Scraping Facebook posts can be an invaluable source of data for research, marketing, or competitive analysis. However, Facebook’s strict privacy policies and constant updates make it challenging to scrape directly. Fortunately, TaskAGI’s Facebook Scraper API provides a solution to safely and efficiently gather the data you need without violating Facebook’s guidelines.
In this blog post, we will walk you through how to use the TaskAGI Facebook Scraper API with Python to extract posts from public pages and profiles. This approach is simple, requires no web scraping skills, and gives you access to a robust API to automate data collection.
Getting Started
Before you dive into the implementation, ensure you have access to TaskAGI’s Facebook Scraper API. You can find the API details at TaskAGI Facebook Scraper or via RapidAPI.
Once you have registered and obtained your API key, you’ll be ready to integrate it into your Python script.
Prerequisites
To use the Facebook Scraper API, you’ll need the following tools and libraries:
- Python 3.6+
requestslibrary to make HTTP requests
Install requests using the following command if it’s not already installed:
pip install requestsExample Script to Scrape Facebook Posts
Here’s a simple Python script to scrape Facebook posts using TaskAGI’s Facebook Scraper API:
import requests
import json
# API details
api_url = "https://taskagi.net/api/social-media/facebook-scraper"
api_key = "YOUR_API_KEY" # Replace with your actual API key
# Parameters for the scraping
payload = {
"target": "public_page_name_or_profile_id", # Specify the target page or profile
"limit": 10 # Number of posts to scrape
}
# Headers with API key for authentication
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
# Make the request to scrape Facebook posts
def scrape_facebook_posts():
response = requests.post(api_url, headers=headers, json=payload)
if response.status_code == 200:
data = response.json()
print(json.dumps(data, indent=4)) # Print the results nicely formatted
else:
print(f"Error: {response.status_code}")
print(response.text)
# Run the function to scrape posts
if __name__ == "__main__":
scrape_facebook_posts()Explanation
- API URL & Authentication: The script starts by defining the API endpoint URL and your API key. Make sure to replace
YOUR_API_KEYwith the actual key you received from TaskAGI. - Payload: The payload defines the parameters for scraping. You can specify the Facebook page or profile ID, along with the number of posts you want to retrieve. Only public profiles or pages can be scraped legally.
- HTTP Headers: The script includes headers for authentication using the API key.
- Request Execution: The function
scrape_facebook_posts()sends a POST request to TaskAGI’s API endpoint. If the request is successful (status code 200), the results are printed in JSON format.
Customizing Your Scraping
TaskAGI’s Facebook Scraper API allows for customization, including filtering posts by date or keywords, extracting comments, or targeting specific post types. For a complete list of available options, refer to the official documentation on TaskAGI’s Facebook Scraper page.
To enhance your script, you might consider adding error handling or saving the data to a CSV or database for future analysis. For instance, you can use the pandas library to organize scraped posts:
import pandas as pd
# Save scraped posts to CSV
def save_to_csv(data):
posts = data.get("posts", [])
if posts:
df = pd.DataFrame(posts)
df.to_csv("facebook_posts.csv", index=False)
print("Saved to facebook_posts.csv")
else:
print("No posts found")Rate Limits and Best Practices
TaskAGI’s Facebook Scraper API is designed to comply with rate limits and minimize load on Facebook servers. Be sure to adhere to the rate limits specified in the API documentation to avoid being blocked.
Additionally, scraping personal information is against Facebook policies and could lead to account suspension. Ensure that you only scrape public data and use the information responsibly.
Conclusion
TaskAGI’s Facebook Scraper API makes extracting data from Facebook straightforward. By using the API, you eliminate the complexities associated with direct web scraping, such as managing changing page structures, browser automation, or IP blocking.
To get started, explore the TaskAGI API documentation and RapidAPI integration to unlock powerful social media data insights.
Feel free to modify the provided script to suit your specific use case. For any questions, drop them in the comments below, and if you found this guide helpful, consider subscribing for more tutorials like this!
Leave a Reply